
A gated linear network is a family of backpropagation-free neural architectures, that utilizes a distributed and local credit assignment mechanism. In a gated linear networks each neuron makes a direct target prediction, and has its own set of hard-gated weights that are locally adapted through online convex optimization. Gated linear networks (GLNs) are capable of modeling any compactly supported, continuous density function to arbitrary accuracy.
Backpropagation enables neural networks to learn highly relevant task specific non-linear feature, but has been criticized for a lack of biological plausibility, the existence of multiple local optima due to performing gradient descent on a non-convex loss function, the susceptibility to catastrophic forgetting, and being difficult for human interpretation. Gated linear networks are meant to be an alternative neural model as the approach they use is known for sample efficiency, and offer competitive performance to existing batch machine learning techniques.
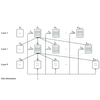
Gated linear networks are feed-forward networks composed of several layers of gated geometric mixing neurons in which each neuron in a given layer outputs a gated geometric mixture of the predictions from the previous layer. The final layer consists of only one neuron which determines the output of the entire network. Each neuron receives two types of input which ultimately provide the prediction of the system. The first input is side information similar to input features on a standard supervised learning setup. The second is the input of the predictions output by the previous layer. Layer zero may be provided with 'base predictions'. Neurons take constant predictions allowing bias weight to be learned, and upon receiving an input, every gate in the network fire, meaning each neuron attempts to predict the target with an associated per-neuron loss.


